RSS Feeds: How to Read News And Stuff Without Bullshit
Lemme skip to how to find RSS URLS for * Youtube * Substack and Wordpress * Reddit * Medium * Videosift
It used to be, back in the day, that when you wanted to have a presence, a voice on the internet to show people stuff you had to have a website. And to do that, either you needed to have the computery skillz to setup your own webserver or pay people to do it. Or use a freemium hosting service like MySpace or Geocities (unrelated, go checkout neocities.org, its back baby).
And then there was the problem of how do people find out when you add new shit to your website? If you were a newspaper, or a company or institution that had STUFF that people wanted to read, it was a bit easier. Chances are people would type www.yourdomain into their web browser manually or have it bookmarked, and they’d visit it every day or so, checking for new stuff. Apart from that the only way news and content spread on the internet was through:
- someone else mentioned and linked the thing from their website
- someone sent the link to you via email or over one of the early “chat” programs like ICQ, Microsoft/Yahoo/AIM messenger or the very early (and shitty but good for their times) real-time chat/voice over IP programs like Teamspeak or Skype (before Microsoft bought it and it sucked)
- you saw the link in a newsgroup, email distribution list, IRC channel or a .plan update. Or a CGI/PHP bulletin board: think self-hosted micro-Reddit websites, one each for people playing certain games or who had foot fetishes; even the nazis; little self-contained bubble echo chambers.
Twittle or TubeTok didn’t exist with their bullshit algorithms so you would only discover something if someone sent it TO you, or you went to go find it.
So into this late 90s, early 2000s void of not getting news shoved into your face, arose RSS or Really Simple Syndication. Basically, anything that produced content, or would periodically produce new or updated content, could also publish an RSS feed. This feed would always exist at the same URL address, and all an interested reader on the internet would have to do to subscribe to that websites stream of very interesting stuff, would be to periodically poll that site’s RSS feed and see what’s new.
Here’s the main “all articles” RSS feed for the Toronto Star, found at https://www.thestar.com/search/?f=rss&t=article&c=news.
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0"
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:georss="http://www.georss.org/georss">
<channel>
<title>www.thestar.com - RSS Results in news* of type article</title>
<link>https://www.thestar.com/search/?f=rss&t=article&c=news*&l=50&s=start_time&sd=desc</link>
<atom:link href="https://www.thestar.com/search/?f=rss&t=article&c=news*&l=50&s=start_time&sd=desc" rel="self" type="application/rss+xml" />
<description>
www.thestar.com - RSS Results
in section(s) news*
only for asset type(s) of article
</description>
<generator>TNCMS 1.72.4</generator>
<docs>http://www.rssboard.org/rss-specification</docs>
<ttl>30</ttl>
<item>
<title>Libya says it suspended oil production at largest field after protesters forced its closure</title>
<description>CAIRO (AP) — Production at Libya’s largest oil field was suspended Sunday, the country’s state-run oil company said, after protesters forced the facility to close over fuel shortages.</description>
<pubDate>Sun, 07 Jan 2024 13:42:38 -0500</pubDate>
<guid isPermaLink="false">http://www.thestar.com/tncms/asset/editorial/31dcf06d-7fcf-53e4-9520-f2587deed7d8</guid>
<link>https://www.thestar.com/news/world/africa/libya-says-it-suspended-oil-production-at-largest-field-after-protesters-forced-its-closure/article_31dcf06d-7fcf-53e4-9520-f2587deed7d8.html</link>
<dc:creator>Samy Magdy The Associated Press</dc:creator>
<enclosure url="https://bloximages.chicago2.vip.townnews.com/thestar.com/content/tncms/assets/v3/editorial/b/48/b48b8604-36d2-5f31-9535-8bcb5a9d7844/659af12d2f84d.image.jpg?resize=300%2C200" length="67488" type="image/jpeg" />
</item>
<item>
<title>Third shooting in three days in Coquitlam, B.C., sends man to hospital</title>
<description>COQUITLAM, B.C. - Mounties in Coquitlam, B.C., say a third shooting in as many days has left a man with life-threatening injuries.</description>
<pubDate>Sun, 07 Jan 2024 13:20:41 -0500</pubDate>
<guid isPermaLink="false">http://www.thestar.com/tncms/asset/editorial/5012996d-44d7-59fd-8baa-34182011f78b</guid>
<link>https://www.thestar.com/news/canada/third-shooting-in-three-days-in-coquitlam-b-c-sends-man-to-hospital/article_5012996d-44d7-59fd-8baa-34182011f78b.html</link>
<dc:creator>The Canadian Press</dc:creator>
<enclosure url="https://bloximages.chicago2.vip.townnews.com/thestar.com/content/tncms/assets/v3/editorial/a/1e/a1e24cb0-d7f1-549c-a70f-4db470e33610/659aec8c313f8.image.jpg?resize=300%2C200" length="182257" type="image/jpeg" />
</item>
At the top there’s some metadata about what type / format of RSS stream this is, then some metadata about the website including some self referencing info for the news reader application... and then individual items, one for each thing in the feed. Here’s one:
<item>
<title>A dog shelter appeals for homes for its pups during a cold snap in Poland, and finds a warm welcome</title>
<description>WARSAW, Poland (AP) — With a deep freeze approaching, an animal shelter in Krakow sent out an urgent appeal to people to adopt or at least temporarily shelter some of its dogs until the dangerous cold spell passes.</description>
<pubDate>Sun, 07 Jan 2024 12:16:44 -0500</pubDate>
<guid isPermaLink="false">http://www.thestar.com/tncms/asset/editorial/44fd1fe5-8d57-5a19-b00a-18539063092b</guid>
<link>https://www.thestar.com/news/world/europe/a-dog-shelter-appeals-for-homes-for-its-pups-during-a-cold-snap-in-poland/article_44fd1fe5-8d57-5a19-b00a-18539063092b.html</link>
<dc:creator>The Associated Press</dc:creator>
<enclosure url="https://bloximages.chicago2.vip.townnews.com/thestar.com/content/tncms/assets/v3/editorial/1/d2/1d28714f-0754-51fa-a49b-df10f12b5163/659add415e9f0.image.jpg?resize=300%2C200" length="213355" type="image/jpeg" />
</item>
Its got a title, a publication date and a description. Depending on the RSS feed, the content of the description could be a traditional news slug (i.e. a short summary or hook like description of the article to get you to click) or it could be the whole body of the article itself.
Here’s what that news article looks like in the news reader I use (yarr – Yet Another RSS Reader):
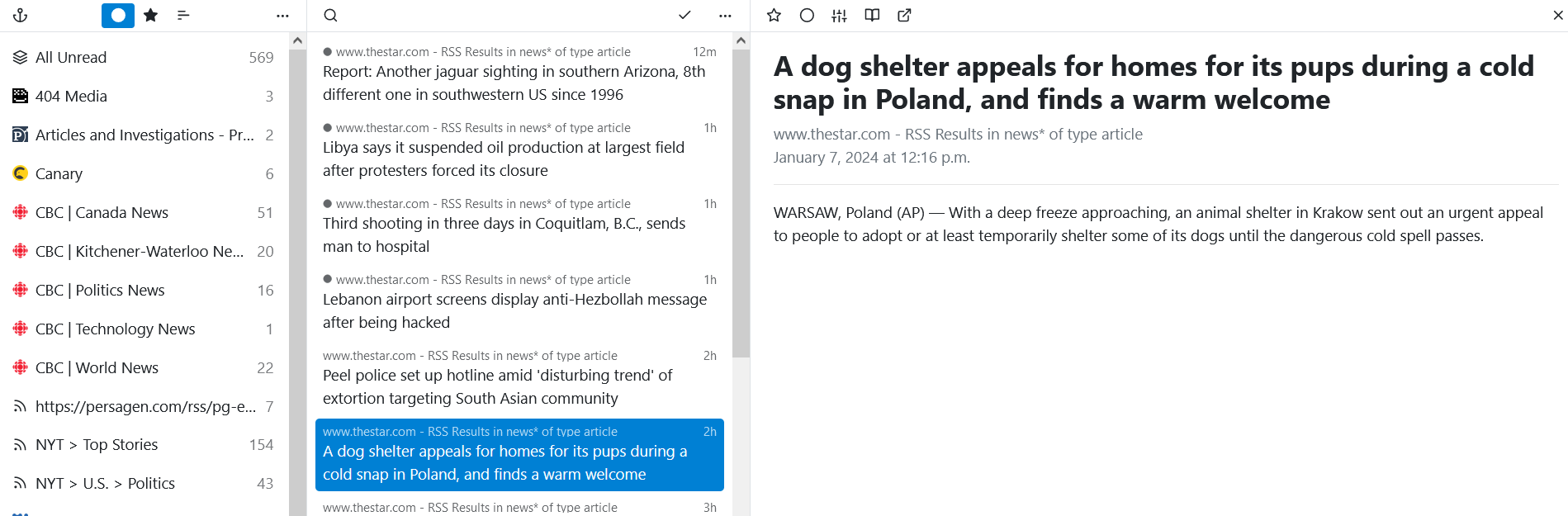
In the left I’ve got a list of all the RSS feeds I subscribe to, the center is the list of articles (or items) in one of those feeds and the right is the content. By default, the Toronto Star’s RSS feed only shows me the headline, byline and the slug. But if I click that Read Here button
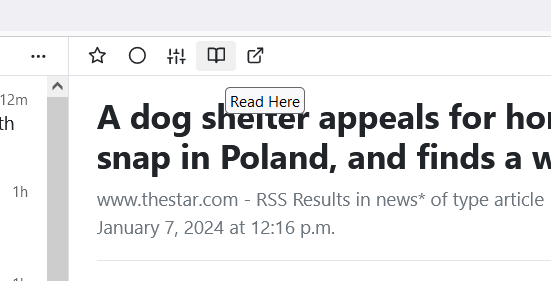
.. my newsreader goes and retrieves the content of the article and displays it here. Woot.
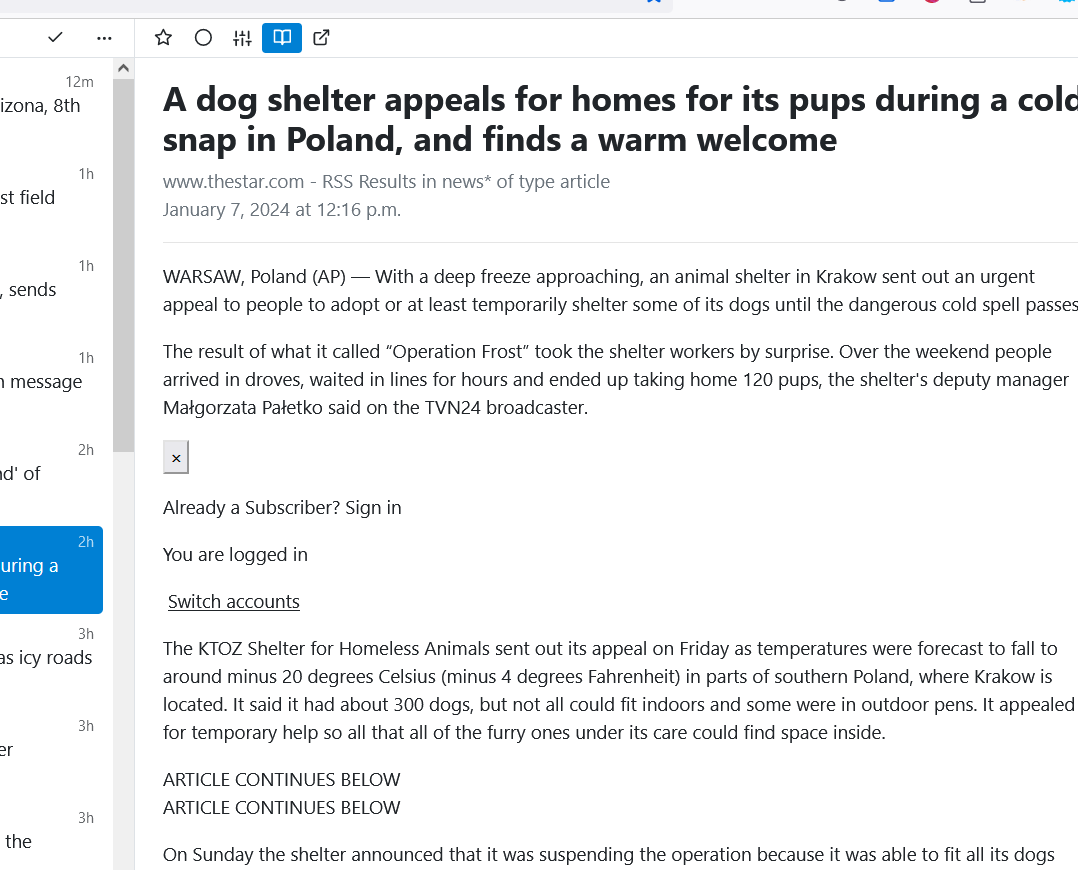
Ok, sometimes this doesn’t get any pictures, but it DOES strip out all the cookie popups, ads, scripting and all the other bullshit. This also (usually) sidesteps any annoying paywalls. The behavior of this depends a lot on a) what newsreader you use and how it behaves b) the nature of the RSS feed and how content is published / linked to it by the content provider.
Well this is pretty cool. Why the hell don’t we get news this way now?
I dunno. The RSS feeds never went anywhere – any content publishing platform that has existed since oh, 1999 or so, has been capable of publishing RSS feeds. And unless the websites that use these platforms deliberately turn them off, they’ve always been there.. still are there.
I think between Yahoo/Google/Bing news “home pages” in your browser, and algorithms in Twitter and Facebook shoving news in our faces (or getting people in our social networks to SEND us stuff) we just fell out of practice of actively going to where the content is and curating our feeds ourselves. Its easy to zone out in front of the TV when there’s a steady drip of just-engaging-enough on the tube; same thing online; if what the algorithm shoves in your face is just engaging enough, we lose interest in finding out the really good stuff that takes a bit of work.
Subscribing to RSS feeds takes back that control. Read only what YOU want to read.
Ok this is nice and all but how do I read these RSS feeds?
Chances are you already have an app that does it. Every major email client made in the last 20 years has had RSS feed reading capabilities. e.g: – outlook: https://www.howtogeek.com/710645/how-to-use-microsoft-outlook-as-an-rss-feed-reader/ – thunderbird: https://blog.thunderbird.net/2022/05/thunderbird-rss-feeds-guide-favorite-content-to-the-inbox/
(not just these, almost everyone I can recall using has been able to to some degree: Forte, Eudora..)
RSS reader apps: Then, you have purpose built RSS reader applications of which I won’t even bother mentioning because I’m sure you can use a search engine/app store.
The problem with using standalone RSS reader apps or using your email client is that if you want to read RSS feed content on another device you have to copy/clone the news feeds that you subscribe to that device. (although there are OPML files which are used to export/import these) And then, you have to manually pick through what you’ve already read on the other device vs. this device. That leads us to:
RSS ‘Feed Aggregators’ services or apps that synchronize between devices: These apps or services let you subscribe to RSS feeds in one spot and read (and keep track of what you’ve read) across multiple devices. Some are websites, some are apps, some are browser plugins.
Again six seconds in any search engine will bring up dozens of these services, but some examples just off the top of my head are Feedly, Feeder, NewsBlur but there are tons of others.
The problem with these is that you gotta create an account and maybe have a subscription... or deal with ads. And you have to use their APP. Whatever happened to just using a web browser. What if I want to self-host my own? You can do that!
Self host your own RSS news aggregator
There are lots out there, and you can find them easily searching for self-hosted RSS aggregator. I’ve tried a few including:
– FreshRSS -https://github.com/FreshRSS/FreshRSS
– TinyRSS -https://tt-rss.org/
.. and more from https://alternativeto.net/software/feedly/?platform=self-hosted amongst others.
The problem I faced is that I just wanted something simple, single-user, doesn’t require a Docker/K8 container; reading the feeds could be done through a browser. AND, I want it served on a custom port. For one, a little security through obscurity, another I already run THIS WriteFreely site on 80 and 443, and I didn’t want to futz around with a reverse proxy – yet.
Enter
Yarr – Yet Another RSS Reader
get it: https://github.com/nkanaev/yarr
You can run Yarr on a desktop – it then self-hosts at localhost:port and puts an icon down in your system tray that launches your browser to that address.
Or you can set it up as a linux service, which is what I have done.
(see below for that)
Where /How do I find RSS feeds for various sites/platforms?
Ok so you’ve got a suitable reader setup, how do you find RSS feeds? If you’re lucky the website will show it to you:
Other times you have to go digging and searching a bit using site search or search engine. For example here’s the Washington Post’s list of RSS feeds:
https://www.washingtonpost.com/discussions/2018/10/12/washington-post-rss-feeds/
Sometimes a blog or a news site doesn’t WANT you to know their RSS address... because if you could use an RSS reader you could doge their cookies, ads, proprietary apps and other bullshit (and we can’t have that happen!) But even though they’re hidden, I bet the RSS is still there, you just have to be sneaky:
Substack / WordPress RSS
Strip off the url, +/feed. Doesn't work with sub-substacks or “channels” i.e. sub-blogs of a larger account.
https://www.snackstack.net+ /feed –> (https://www.snackstack.net/feed)
Reddit RSS
You can subscribe to individual subreddits (OR users) by simply tacking /.rss onto the end of the subreddit or user URL – each new top level post/thread is an item in RSS parlance, and you don’t get the comments and replies. (ugh, you’ll have to use the Reddit app like a filthy commoner)
https://www.reddit.com/r/canada/.rss
https://www.reddit.com/u/tezoatlipoca/.rss
(how long before they close THIS hole I wonder?)
Medium RSS
Medium is actually up front about theirs, good job Medium. https://help.medium.com/hc/en-us/articles/214874118-Using-RSS-feeds-of-profiles-publications-and-topics
except for paywalled content all you’ll get is the slug essentially.
VideoSift RSS
You can get a stream of everything submitted, but before its “sifted” https://videosift.com/.rss
You can also RSS subscribe to individual user posts: https://videosift.com/motorsports/rss2/newtboy/member.xml and their bookmarks: https://videosift.com/motorsports/rss2/newtboy/memberfav.xml (these are on their user page)
but you can’t follow channels or tags
Youtube RSS
Find the Youtube channel URL you want to follow: https://www.youtube.com/channel/UCRarNme4iUanPLflogg-Ntg
Now take that channel ID off the end and tack it to the end of this:
https://www.youtube.com/feeds/videos.xml?channel_id=
voila, RSS feed: https://www.youtube.com/feeds/videos.xml?channel_id=UCRarNme4iUanPLflogg-Ntg
thanks to https://danielmiessler.com/p/rss-feed-youtube-channel/ for this one.
What if I can’t find the RSS feed?
A lot of RSS aggregator services have “scraping” capabilities, where they’ll scrape the webpage in question and generate a feed for you. (yarr doesn’t do this, it only works on a well formed rss file)
If you have a website that you want to generate an RSS feed from and can’t figure out how, msg me at @tezoatlipoca@mas.to and maybe I can figure out how.. but really all Ill be doing is using a search engine. But, figure out how to get RSS from a website I haven’t mentioned, msg me and Ill add it here!
Yarr linux installation
- grab the source and compile or grab the prebuilt binary of your choosing
- dump the binary somewhere (
/usr/local/bin/yarr/yarr) and chmod appropriately for execution by users write a user script (
/home/<user name>/yarr.sh)that launches said application and chmod for execution ONLY by that user:#!/bin/bash /usr/local/bin/yarr/yarr -addr "<ip to bind to>:<port>" -auth <user name>:<user yarr pwd not their system pwd> > /var/log/yarr.log 2>&1make sure
userabove has permission to write to that log file (otherwise yarr won’t run)If you want to run it as is, just run the script. If you want to install it as a system service that autostarts, create a systemd file that identifies this as a system service:
[Unit]
Description=Yarr.<user>
After=network.target
[Service]
Type=simple
User=<user>
Restart=always
ExecStart=/home/<user name>/yarr.sh
[Install]
WantedBy=multi-user.target
- register and start the service.
When it runs, yarr will host itself at <host/ip>:<port> and it will prompt for the credentials specified on the command line in yarr.sh. Its database of rss feeds and read status is stored at /home/<user>/.config/yarr/storagedb as a single self-contained sqlite database file, so whatever user/home backup system you have in place will automatically snab user yarr info too.
By changing the user and ports used in the launching script file (and creating suitable systemd entries) you can create a custom yarr instance for multiple users.
Changelog
2024-01-07 – initial 2024-01-07A – moved yarr config to bottom. + toc